
How To Respond To Google’s Latest Warning – “Googlebot Cannot Access Your Javascript and CSS Files”

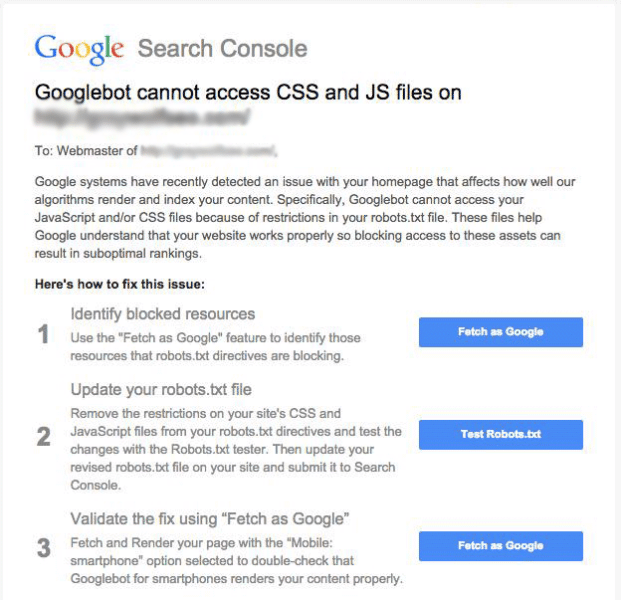
Here are a couple things you need to know.
The message in Search Console is new, but Google’s initiative isn’t.
 Google wants access to crawl EVERYTHING. The message is for those sites where Google can’t crawl everything efficiently or accurately.
Google wants access to crawl EVERYTHING. The message is for those sites where Google can’t crawl everything efficiently or accurately.
The message says that this issue “can result in suboptimal rankings”.
This message would appear as a low impact as a search ranking factor. As the ranking factor itself is not new, there should be no drastic decrease on your account.
If the warning is received, fixing the problem is fairly easy.
If you manage your website account and are comfortable making edits to your robots.txt file, go ahead with the steps below. If you’re not comfortable making changes to your website contact your site’s webmaster for an update. For client’s of Boostability, your Account Manager can address any concerns you have or changes needed.
Steps from Search Engine Land on how to fix your robots.txt file:
Look through the robots.txt file for any of the following lines of code:
Disallow: /.js$*
Disallow: /.inc$*
Disallow: /.css$*
Disallow: /.php$*
If you see any of those lines, remove them. That’s what’s blocking Googlebot from crawling the files it needs to render your site as other users can see it.
After these steps are completed, you’ll want to run your site through Google’s Fetch and Render tool to confirm the problem is fixed. If you are still experiencing problems, your Fetch and Render tool will provide further instructions on changes that need to be made.
In addition to Google’s Fetch tool, you can use the robots.txt tool in your Search Console to identify any remaining issues in crawling your website.
Very helpful, thanks! One question – is there any reason (security or otherwise) a webmaster would NOT want to allow Googlebot access to these files?
Great question Jason. Ultimately it is up to the webmaster. Most these bits of information don’t pose a security threat in any way. It should be rare for a local business to block pages.
Thanks for the insight!
Me and my team were actually just discussing this issue this morning, as several of our accounts have received these warnings. We were already taking these steps, so it’s good to know that we were heading in the right direction!
Good call Risa! I personally don’t think it is a huge deal as far as rankings are concerned, but it is good to fix when possible.
Hopefully some of the information is this post as well as some of the comments help you know how to fix it!
We have been seeing this a lot lately and in most cases WordPress sites are blocking wp.content files and Google wants to be able to access them.
I have seen that too. What is interesting is I don’t think that Google NEEDS to see that information, mostly just that they want to see that information.
They want to know it all!
That’s absolutely true. It seems to be a CRM issue. Sites like WordPress are doing it all wrong.
Thanks for the tip, Kyle!
Thank you for sharing this information Caz. personally I haven’t experience or have to deal with this issue so far.
That’s good to hear!
I have read some information on blocking pages that if there is a page you want to block instead of including it in the robots.txt file that it is better to put a no index tag on the page.
I have found, especially in WordPress, that a no follow just means that seo credit for linking to or out of that page isn’t traced. The page is still very much searchable, however. That’s why our “no follow” “robots” Social Media Challenge blog was updated back to the Knowledge Base as an intranet accessed page only. In just searching “Caz Bevan” online, it came up as one of the higher results despite the no follow.
Thanks for adding that info!